SLC and MLC NAND Flash Are Equally Reliable on SSDs
Over the weekend a report titled ‘Flash Reliability in Production: The Expected and the Unexpected‘ was published that was written by Professor Bianca Schroeder of the University of Toronto, and Raghav Lagisetty and Arif Merchant of Google Inc. The report is similar to the enterprise hard drive failure rate data released by Blackblaze, but focuses on NAND Flash reliability found on enterprise Solid-State Drives (SSDs) in data centers.

The report uses a very large test pool of drives. We are talking a large-scale study covering many millions of drive days, ten different drive models, different flash technologies (MLC, eMLC, SLC) over 6 years of production use in Googles data centers. The report didn’t get into what exact brands and models were used, but did show failure rates based on the different types of NAND Flash technology that each particular model was using.
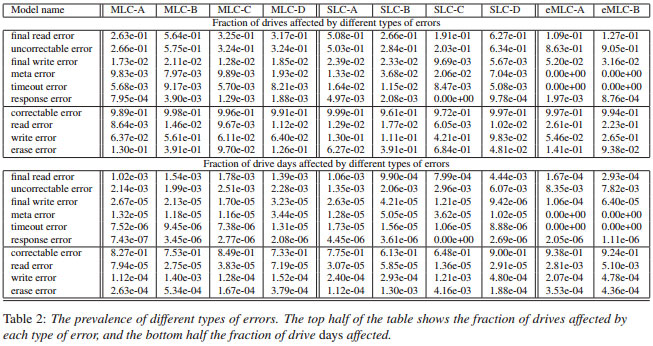
Some of the findings and conclusions might be surprising.
- Between 2063% of drives experience at least one uncorrectable error during their first four years in the field, making uncorrectable errors the most common non-transparent error in these drives. Between 26 out of 1,000 drive days are affected by them.
- The majority of drive days experience at least one correctable error, however other types of transparent errors, i.e. errors which the drive can mask from the user, are rare compared to non-transparent errors.
- We find that RBER (raw bit error rate), the standard metric for drive reliability, is not a good predictor of those failure modes that are the major concern in practice. In particular, higher RBER does not translate to a higher incidence of uncorrectable errors.
- We find that UBER (uncorrectable bit error rate), the standard metric to measure uncorrectable errors, is not very meaningful. We see no correlation between UEs and number of reads, so normalizing uncorrectable errors by the number of bits read will artificially inflate the reported error rate for drives with low read count.
- Both RBER and the number of uncorrectable errors grow with PE cycles, however the rate of growth is slower than commonly expected, following a linear rather than exponential rate, and there are no sudden spikes once a drive exceeds the vendors PE cycle limit, within the PE cycle ranges we observe in the field.
- While wear-out from usage is often the focus of attention, we note that independently of usage the age of a drive, i.e. the time spent in the field, affects reliability.
- SLC drives, which are targeted at the enterprise market and considered to be higher end, are not more reliable than the lower end MLC drives.
- We observe that chips with smaller feature size tend to experience higher RBER, but are not necessarily the ones with the highest incidence of non-transparent errors, such as uncorrectable errors.
- While flash drives offer lower field replacement rates than hard disk drives, they have a significantly higher rate of problems that can impact the user, such as uncorrectable errors.
- Previous errors of various types are predictive of later uncorrectable errors. (In fact, we have work in progress showing that standard machine learning techniques can predict uncorrectable errors based on age and prior errors with an interesting accuracy.)
- Bad blocks and bad chips occur at a signicant rate: depending on the model, 30-80% of drives develop at least one bad block and and 2-7% develop at least one bad chip during the first four years in the field. The latter emphasizes the importance of mechanisms for mapping out bad chips, as otherwise drives with a bad chips will require repairs or be returned to the vendor.
- Drives tend to either have less than a handful of bad blocks, or a large number of them, suggesting that impending chip failure could be predicted based on prior number of bad blocks (and maybe other factors). Also, a drive with a large number of factory bad blocks has a higher chance of developing more bad blocks in the field, as well as certain types of errors.
You can download the full PDF report here that was released during the FAST 16 USENIX Conference on File and Storage Technologies in Santa Clara, California last week.